actionrecognition
Human Activities Recognition by Fusing Multiple Sensors
Supervisors :
Prof. Dr.-Ing. Klaus-Dieter Kuhnert
Dipl.-Inform. Jens Schlemper
Advisors :
PD Dr. habil. Rudolph Triebel (DLR)
Dr. Haider Ali (DLR)
Department of Electrical Engineering & Computer Science, and Department of Perception and Cognition, DLR
Institute of Real-Time Learning Systems (Echtzeit Lernsysteme (EZLS)) and Institute of Robotics and Mechatronics Center
Submitted by:
Kerolos Ghobrial
Matr. Nr: 1120651
Abstract
Human Activity Recognition (HAR) plays an important role in many applications such as surveillance, health-care, assistive living, human machine interaction, robotics and entertainment, etc. Accordingly, it has got an increasing attention in recent years. There are many aspects that should be considered when recognizing human activities such as suitability for real-time, multiple subjects, background scenes, moving camera, stability in the variation in illumination, rotation, viewpoint and the scale of the subject.
Two fusion systems have been introduced in order to improve the (HAR); (1) the first fusion system combines the depth features from the Kinect camera and statistical features from inertial sensors at intermediate fusion stage, and then a late fusion scheme is used to combine the output probabilities from different classifiers, and (2) the fusion of inertial and skeleton data at the early stage is allowed to extract view-invariant features. The late fusion of skeleton and 'skeleton+IMU' contributes to achieving better recognition accuracy than the utilization of single source data.
I. Related Work
Previous work has been organized into three groups at their way to identify activities by fusing multiple sensors:
- First group: depth camera and inertial sensors have been used to recognize actions at two different levels of fusion [1,3,10,9].
- Second group: skeleton information and inertial data at early level of fusion have been used to identify falling and few actions without involving machine learning algorithms [11,12].
- Third group: depth camera and inertial sensors have been used to detect whether a subject falling down or not, involving machine learning algorithms [13,14].
II. METHODOLOGY
A. First Fusion System of Inertial and Depth data:
There are two types of fusion utilized in this method; the first one Feature-level Fusion (FF) is applied only in the depth data by concatenating the three histogram feature vectors Local Local Binary Patterns from Depth Motion Maps (DMMs).
The Statistical Features are extracted from IMU sensors are mean, variance, standard deviation and root mean square. The best number of the time window is 6 and 50 % overlapping moving windows.
Furthermore, it is not efficient to fuse the extracted feature vectors from different sensors to large feature vector since if one of the sensors (depth sensor) has higher dimensional feature vector than the other (IMU sensors) without using any techniques to find a discriminative low dimensional representation of different sensors or without applying any preprocessing step such as (feature normalization) to modify the scale of feature values. However, FF suffers from some drawbacks for usage in real time.
The second one Decision-level Fusion (DF) is combining distinct classification results into a final decision is to use the discriminative features from different modalities, compute two different types of classifiers (l2-CRC for the statistical features from Inertial sensors and Kernel Extreme learning machine (KELM) for DMM-LBP-FF features from Depth sensor), and then merge the probability outcomes by using Logarithmic Opinion Pool (LOGP) fusion method for generating a final label class.
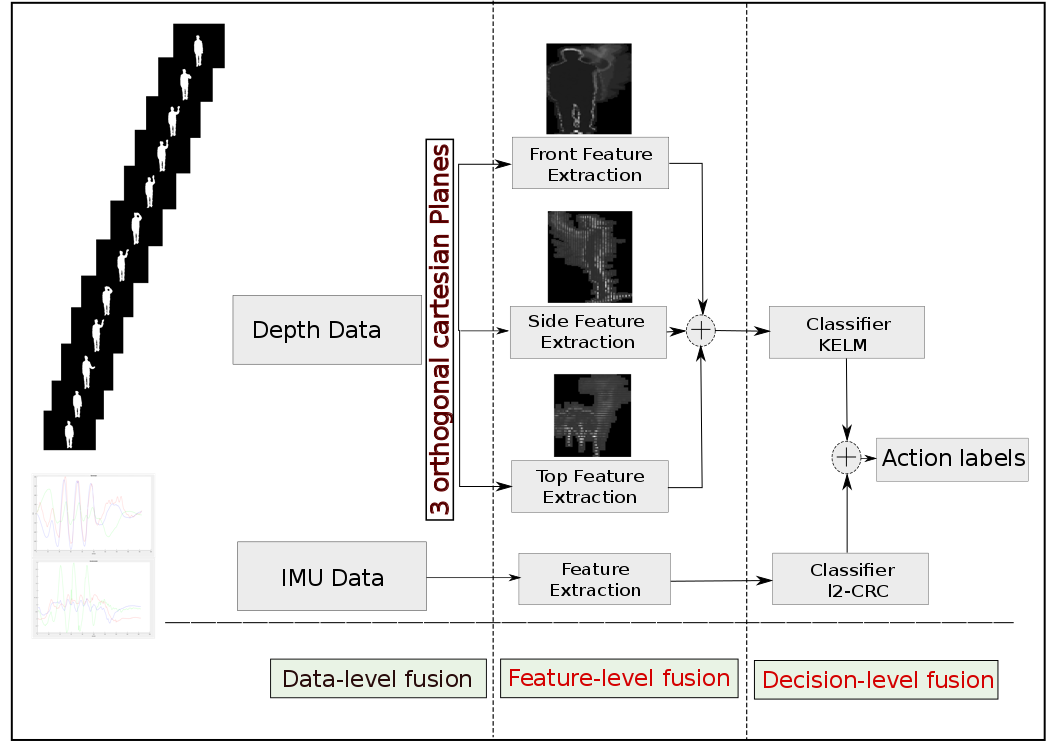
Figure 1: An overview of the proposed method, three histogram features extracted from depth data and concatenating in one feature vector feature-level fusion. Decision-level fusion is used to merge the outcomes of the two different classifiers (CRC classifier from IMU sensors and KELM classifier from Depth sensor) to enhance the overall performance rate.
B. Second Fusion System of Inertial and Depth data:
Two types of fusion were used in this framework; the first fusion (Data-level fusion) is used for extracting global relative features from skeleton data, and relative local features from inertial and skeleton data. The second fusion (Decision level fusion) is used for enhancing the overall classification process by merging the output of two classifiers.
This proposed method is very convenient and efficient for trying to solve the most problematic issues in the field of human action recognition which are view and time variant action detection. By extracting view-invariant features from different modalities and by using a state model-based classifier ’Gaussian Mixture Model based Hidden Markov Model’ (GMM-HMM), which is more robust for recognizing the action at different speeds. Furthermore, Bakis HMM model topology is used to give an additional opportunity to perform online because each action has its own Hidden Markov Model.
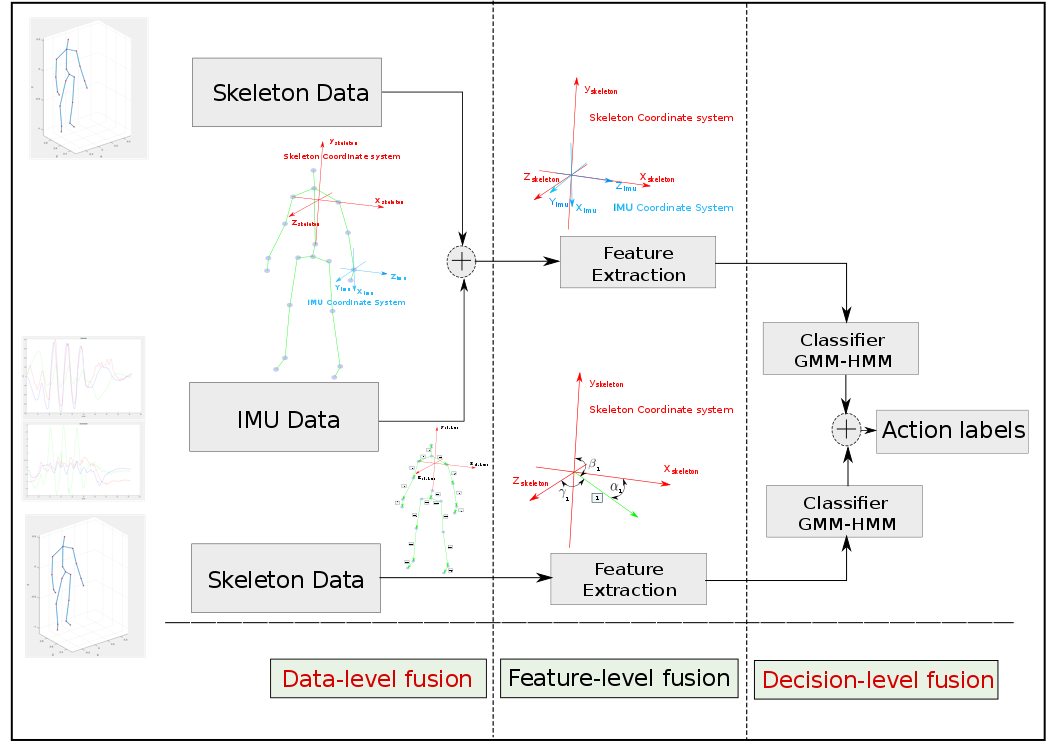
Figure 2: An overview of the proposed algorithm, Orientation meaningful features extracting from raw data using both skeleton and IMU sensors in Data-level fusion simultaneously. These features are used to capture the specific movements of parts of the human body (local features). Using skeleton data from Kinect sensor, orientation angle features were extracted to capture the full body movements (global features). Then, these two features are fed into two GMM-HMM classifiers. Decision fusion approach is applied to combine the probability output of both classifiers, and then the action with the highest probability is considered as the most likely action.
1. Data-Level Fusion of Inertial and Skeleton Data
Madgwick algorithm is used to obtain the orientation from IMU sensors which has many advantages over Kalman-based algorithm in terms of the inexpensive computation and can work more effectively at low sampling rates [5].
To extract features from inertial sensors and skeleton simultaneously, the angles between each vector in IMU coordinate system (X,Y and Z) with respect to skeleton coordinate system are calculated. Because most of the actions started with the same postures (pose), which the (UTD-MHAD) dataset had recorded [1] mapping between the two spatial coordinates is possible. Only the way to link the orientation between two types of sensors (skeleton and inertial sensors) by using (Orientation angles fusion approach) has been mentioned.
The synchronization method between these two sensors might be useful in this case, which is explained in [2], by correlating the closest inertial signal (that is almost higher frequency than the RGB-depth camera) to the depth frame, which had been done by using timestamps.
2. Human Action Recognition using Skeleton Features
The key to extract relative view-invariant features is to create a moving reference frame in the human body itself that can help to represent any joints position and any bone vectors with respect to the human body coordinate system.
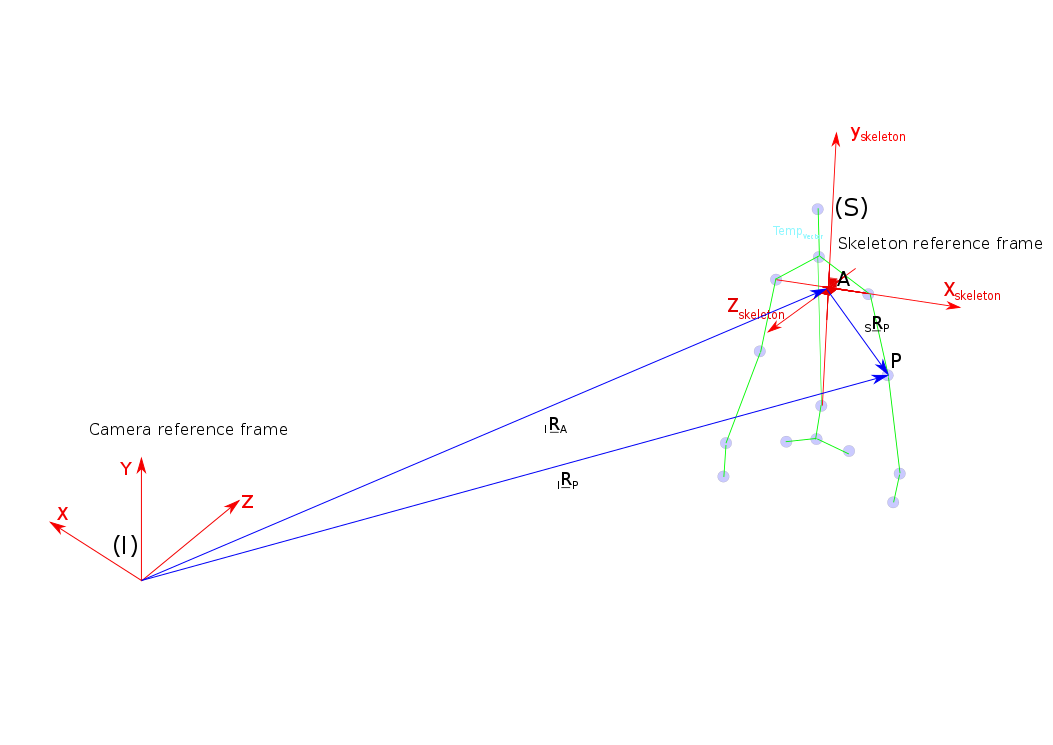
Figure 3: Different reference frames: the fixed reference frame (camera reference frame) I and moving skeleton reference frame S, which is fixed on the moving human body.
-
The First Extracted Features:
Spatial-Temporal Orientation of relative Joints is the orientation between the most discriminative bone vectors on the human body with respect to the skeleton coordinate system.
- The feature vector per each sample is represented as: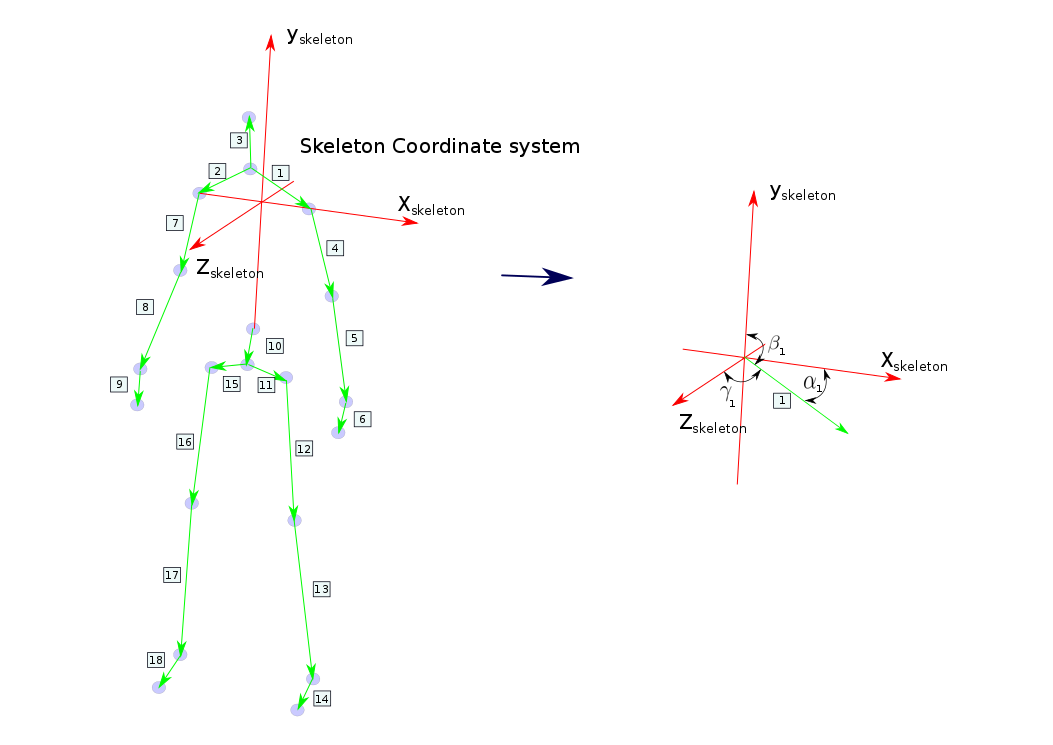
Figure 4:Orientation-Based Representations from skeleton data which contains 18 vectors. Each vector has three components angles.
-
The Second Extracted Features:
Spatial-Temporal Displacement between original skeleton coordinate system and all Joints.
- The feature vector per each sample is represented as: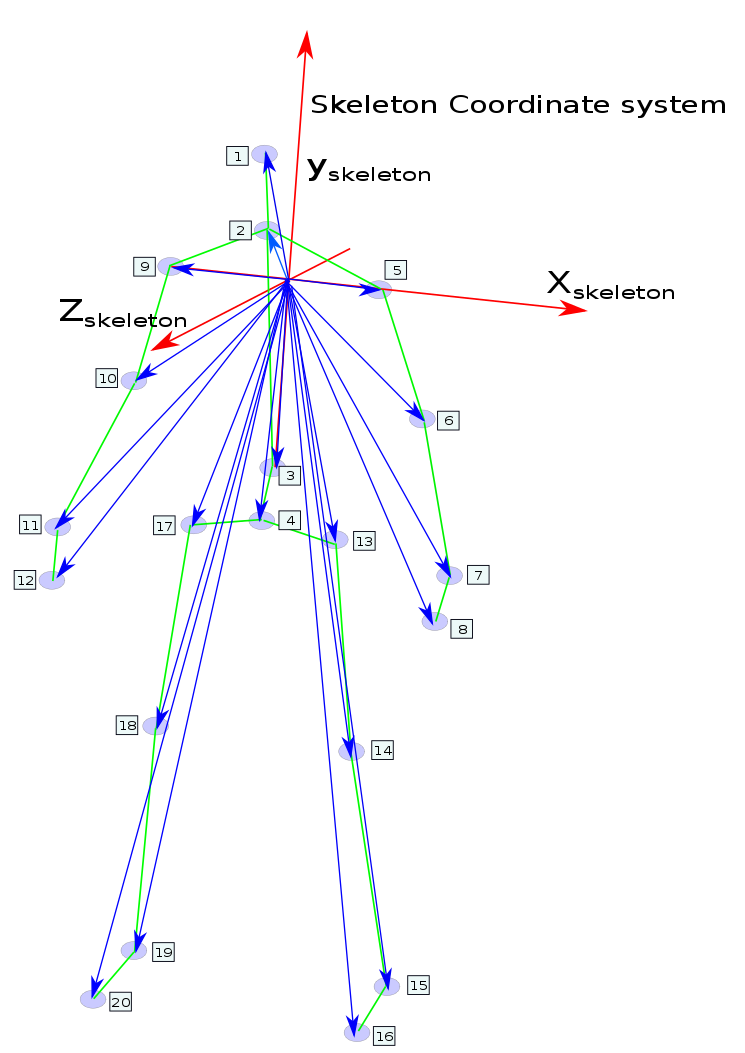
Figure 5:Displacement-Based Representations from skeleton data which contains 20 vectors.
-
The Third Extracted Features:
Spatial-Temporal Spherical Displacement: is the displacement of 15 vectors in the spherical representation of the most discriminative joints, from the center of skeleton coordinate system to these joints: 1)elbow left, 2) wrist left, 3) hand left, 4) hip left, 5) knee left, 6) ankle left, 7)foot left, 8) elbow right, 9) wrist right, 10) hand right, 11) hip right, 12) knee right, 13) ankle right, 14) foot right and 15) head.
- The feature vector per each sample is represented as: -
Displacement Normalization
Converting the skeleton features to be invariant in the human body (scale-invariant feature)
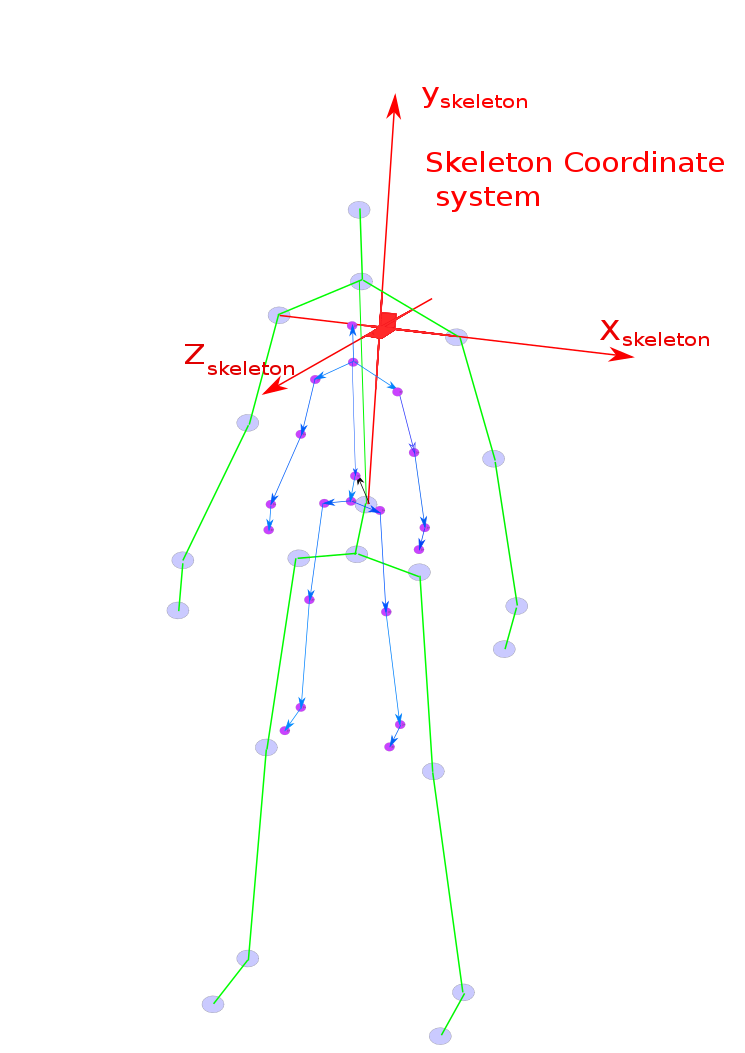
Figure 6: Displacement Normalization of the skeleton data to be invariant with respect to size of human body.
3. Decision-Level Fusion of Inertial and Skeleton Data
By fusing multiple GMM-HMM classifiers, the overall accuracy is dramatically increased by pooling the likelihood probability of GMM-HMM 'IMU+Skeleton' classifier with GMM-HMM 'Skeleton' classifier to produce the overall probability that enhances the output class label overcoming the limitations of each classifier.
III. IMPLEMENTATION AND EXPERIMENTAL RESULTS
- First Fusion System Classification:
There are two supervised classification algorithms which are used in the work to accomplish the recognition task. The first classifier is Collaboration Representation Classifier (CRC) [8]. The second classifier is Kernel Extreme learning machine (KELM) [6,7].
- Second Fusion System Classification:
As each subject performs the same action at a different rate, the probabilistic graphical model such as Hidden Markov Model (HMM) can be an optimal classifier for detecting activities (it has a powerful ability of building a sequential model). Every action is defined as a statistical model with a number of states, which generates sequences of features with a certain probability [4]. In this work HMM based on GMM was implemented for modeling a continuous information from body parts.
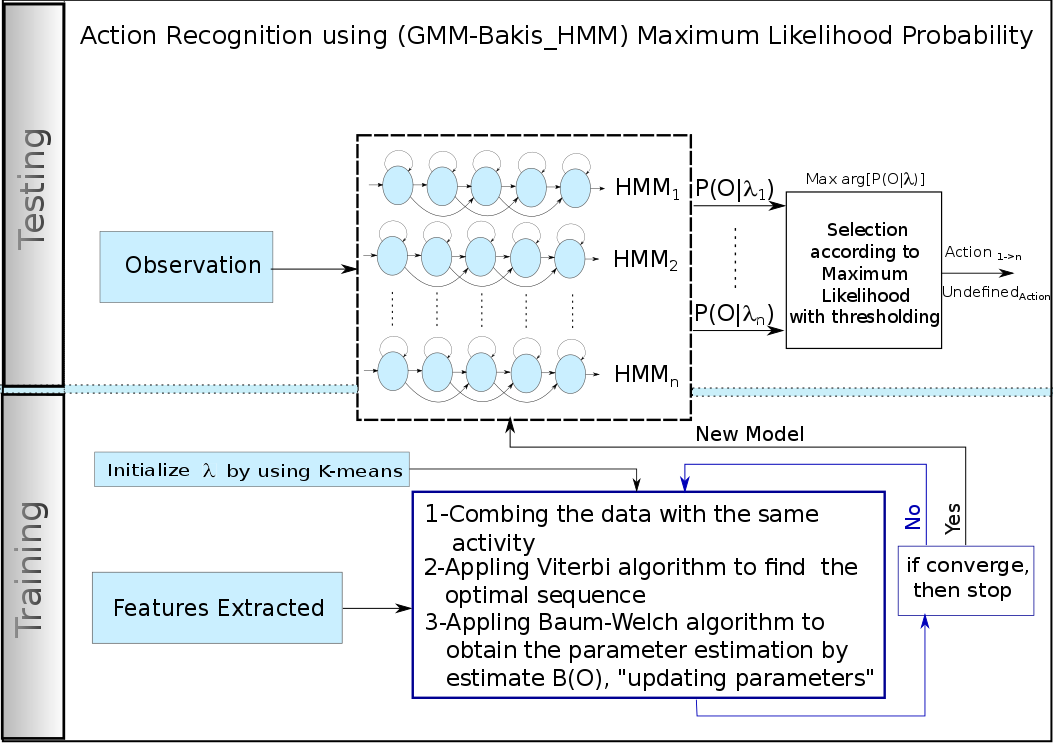
Figure 7: The classification procedures for Training process: the Features have been extracted to establish (GMM based HMM) separated Model for each action. For Testing process: the sequence of observation features have been captured, then the selection should be made according to the model which gives the highest posterior probability, or it will be rejected if it is less than the defined threshold.
A. Dataset
The multimodal human action dataset (UTD-MHAD) [3] was collected by the university of Texas at Dallas in 2015, which had been utilized to evaluate any action recognition algorithm. It had been collected by using the Kinect v1 (RGB videos, depth videos, 20 skeleton joints position) with the frame rate of approximately 30 frames per second and a color image with a resolution of 640×480 pixels and a 16-bit depth image with a resolution of 320×240 pixels, and only one inertial sensor (acceleration and angular velocity) with the sampling rate 50 Hz. its measuring range is ±8g for acceleration and ±1000 degrees/second for rotation. The 27 activity types are: 1.right arm swipe to the left, 2.right arm swipe to the right, 3.right hand wave, 4.two hand front clap, 5. right arm throw, 6.cross arms in the chest, 7.basketball shoot, 8.right hand draw X, 9.right hand draw circle (clockwise), 10.right hand draw circle (counter-clockwise), 11.draw triangle, 12.bowling (right hand), 13.front boxing, 14.baseball swing from right, 15.tennis right hand forehand swing, 16.arm curl (two arms), 17 tennis serve, 18.two hand push, 19.right hand knock on door, 20.right hand catch an object, 21.right hand pick up and throw, 22.jogging in place, 23.walking in place, 24.sit to stand, 25.stand to sit, 26.forward lunge (left foot forward), 27.squat (two arms stretch out). This dataset is performed by 8 human subjects (4 females and 4 males). Each subject performs an activity 4 times. Moreover, this dataset contains only 861 recorded data, due to the corruption of three sequences data. The proposed method is evaluated on "The University of Texas at Dallas multi-modal human action dataset (UTD-MHAD)" that is explained in section [3]. It has many advantages such as the activities executed in different variations of style. Furthermore, most of the actions had been started with the same posture which gives a benefit for implementing this proposed algorithm.

Figure 8: University of Texas at Dallas multi-modal Human Action Dataset (UTD-MHAD), 27 activities.
B. Experiment results
According to the benchmark used in this paper [3], there are two types of experiments. The cross validation (5-fold) was performed to choose the optimal number of states (Q) for GMM-HMM. Furthermore, there are two types of GMM (Full covariance GMM and Diagonal covariance GMM) utilized in this work.
- 1. Subject-generic: The first experiment is called (subject-generic (unseen person)): for each activity, only one subject is considered as testing, and the seven remaining subjects are considered as training.
-
First Fusion System of Inertial and Depth data:
subject-generic (unseen person):
(1) Only sensor data generated from the IMU sensors are used (63.55 %) CRC.
(2) Only the depth camera-related data are considered (77.57 %) KELM.
(3) Both IMU and depth data are involved. (88.79%).
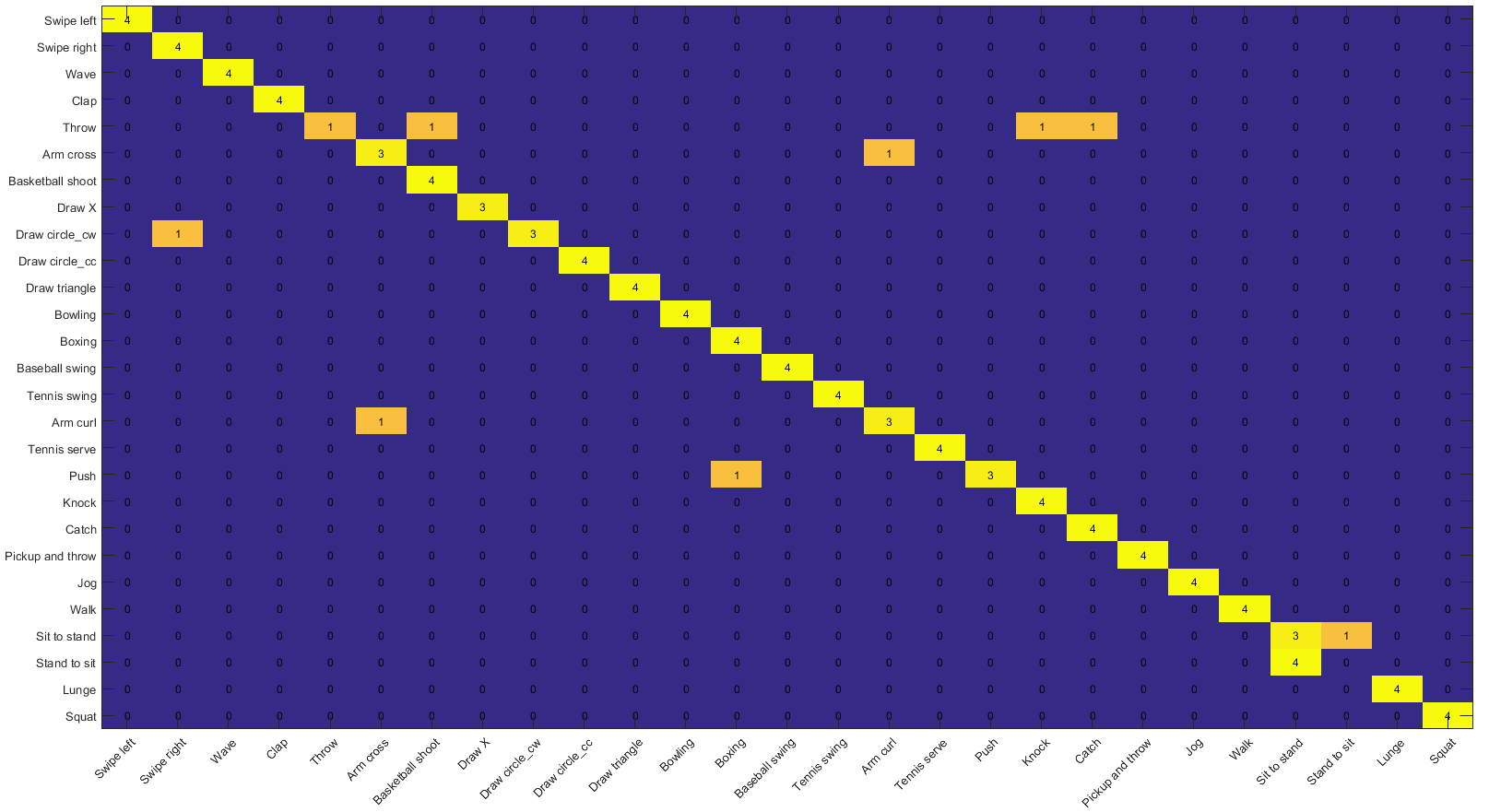
Figure 9: Confusion matrix of Decision Fusion of IMU (CRC classifier) and Depth KELM classifier) classifiers, on the UTD-MHAD dataset for the subject generic experiment.
-
Second Fusion System of Inertial and Skeleton
data: subject-generic (unseen person):
(1) Data-Level Fusion of Inertial and Skeleton Data (85.98 %) GMM-HMM.
(2) Only the Skeleton (82.40 %) GMM-HMM.
(3) Decision Fusion. (96.26%).
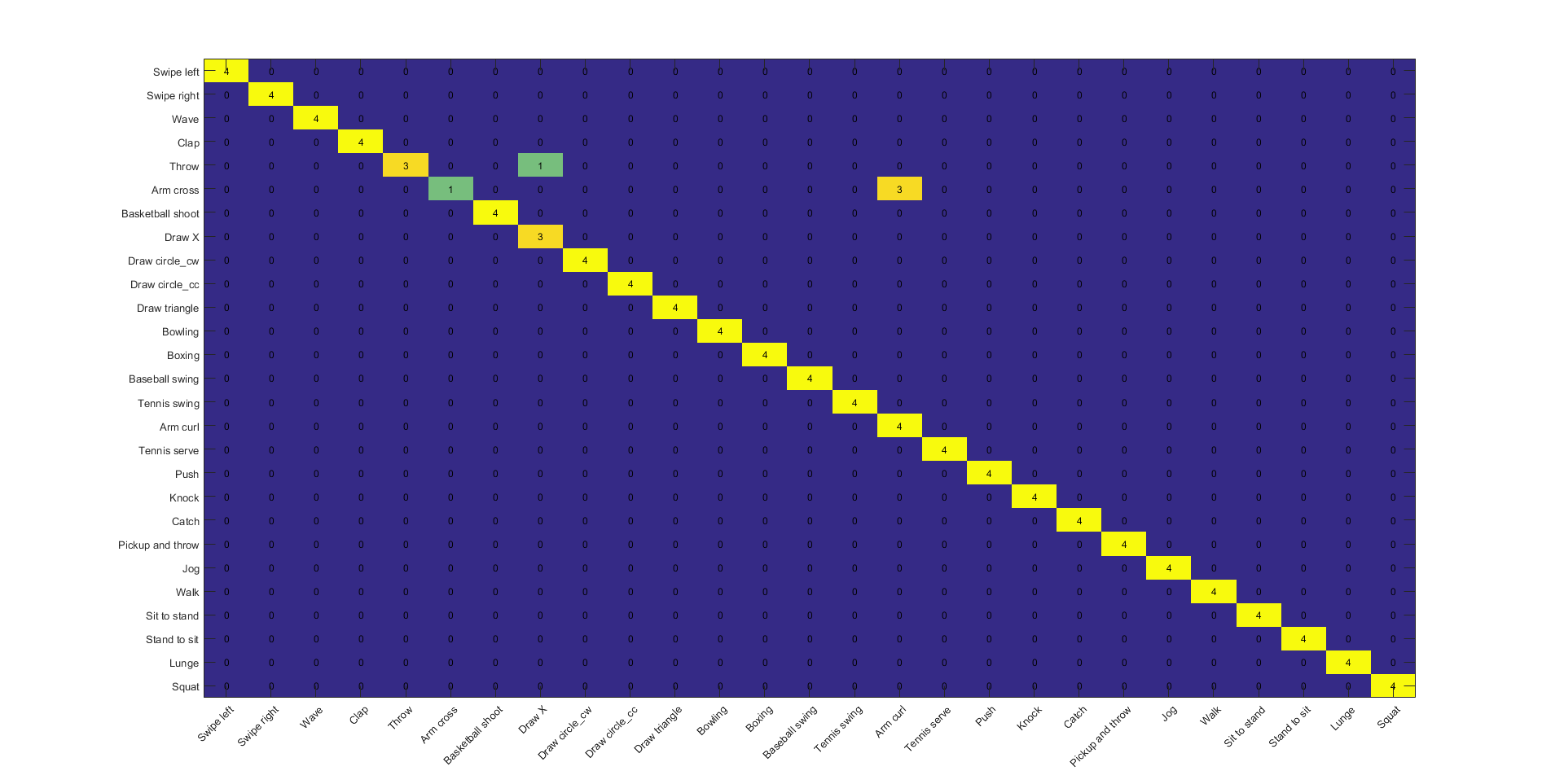
Figure 10: Confusion matrix of Decision Fusion of Skeleton and IMU+Skeleton classifiers, for the subject generic experiment.
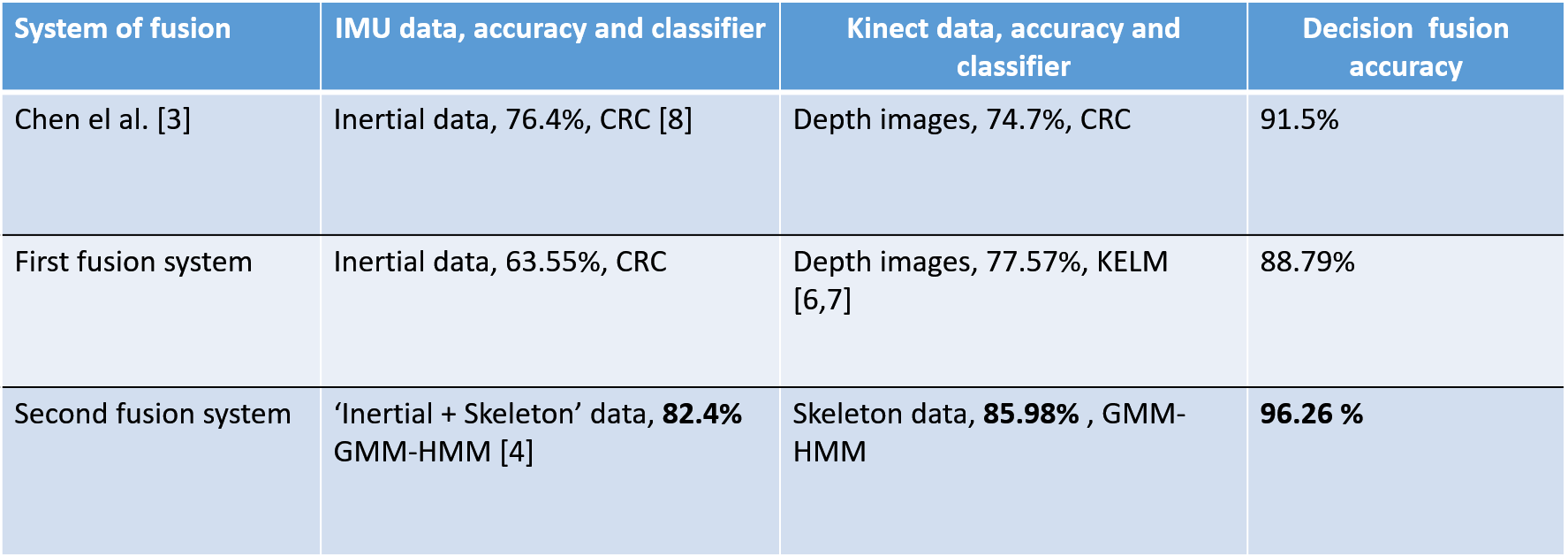
Table 1: Compare recognition accuracy of the proposed method on the UTD-MHAD dataset with state of the art in the subject generic experiment.
- 2. Subject-specific: The second experiment is called (subject-specific (previously seen person)) : each subject performed an action 4 times, the first two samples are considered as training set and the last two samples are considered as a testing set
-
First Fusion System of Inertial and Depth data:
subject-specific (previously seen person): ):
(1) Only sensor data generated from the IMU sensors are used (91.61 %) CRC.
(2) Only the depth camera-related data are considered (92.77 %) KELM.
(3) Both IMU and depth data are involved. (98.83%).
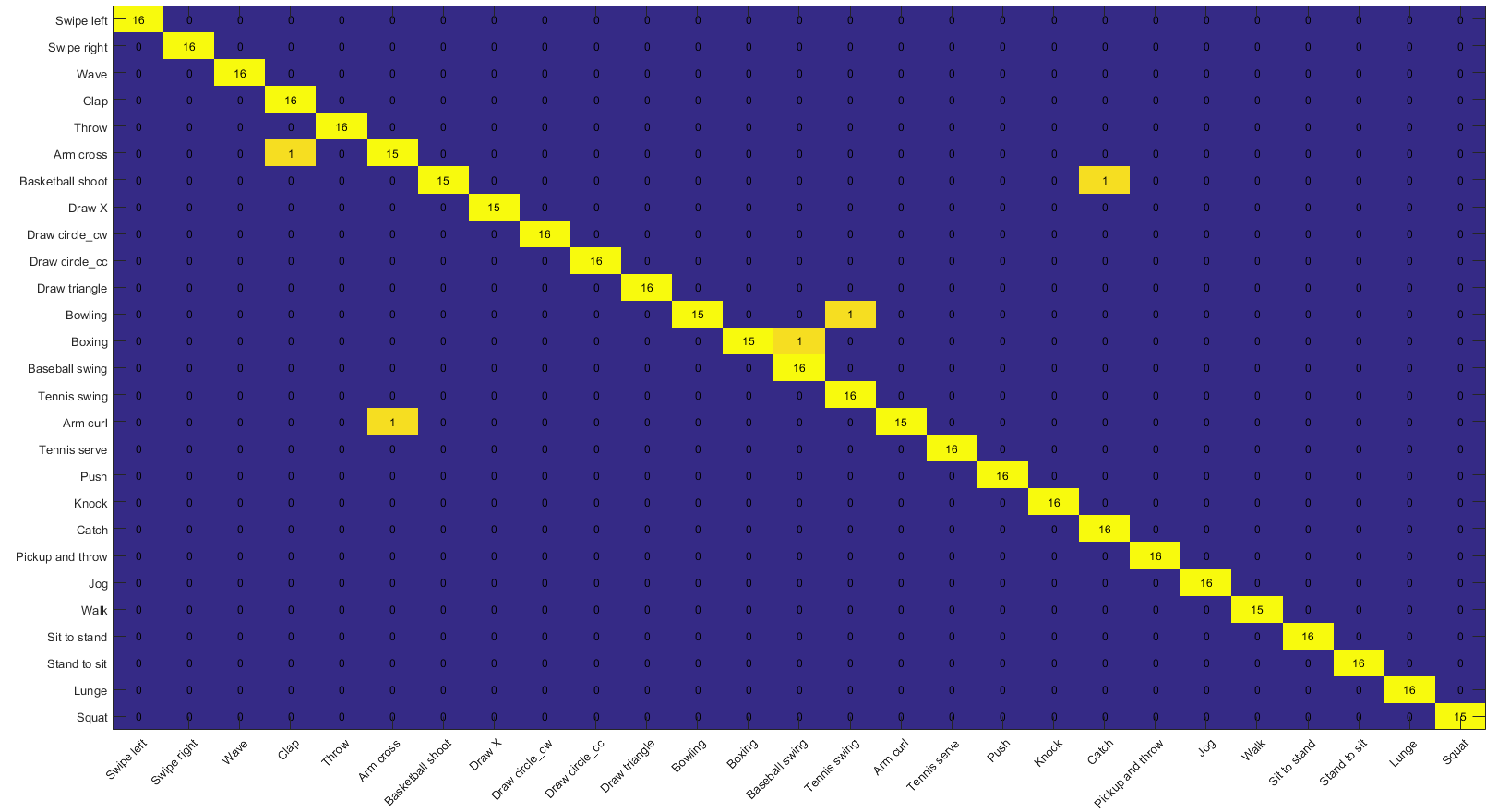
Figure 11: Confusion matrix of Decision Fusion of IMU (CRC classifier) and Depth KELM classifier) classifiers, on the UTD-MHAD dataset for the subject specific experiment.
-
Second Fusion System of Inertial and Skeleton
data: subject-specific (previously seen person):
:
(1) Data-Level Fusion of Inertial and Skeleton Data (94.17 %) GMM-HMM.
(2) Only the Skeleton (95.80 %) GMM-HMM.
(3) Decision Fusion. (98.37 %).
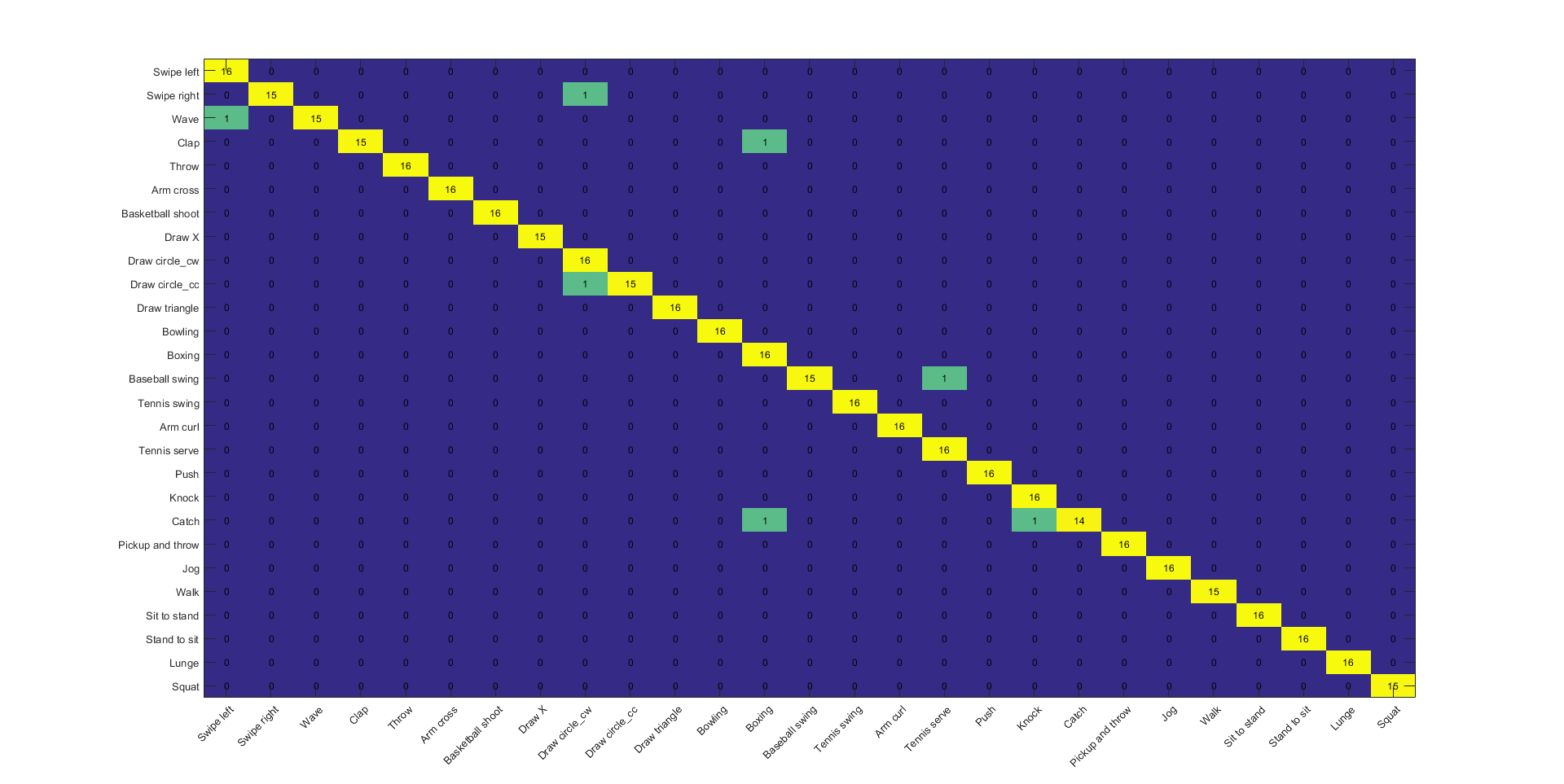
Figure 12: Confusion matrix of Decision Fusion of Skeleton and IMU+Skeleton classifiers, for the subject specific experiment.
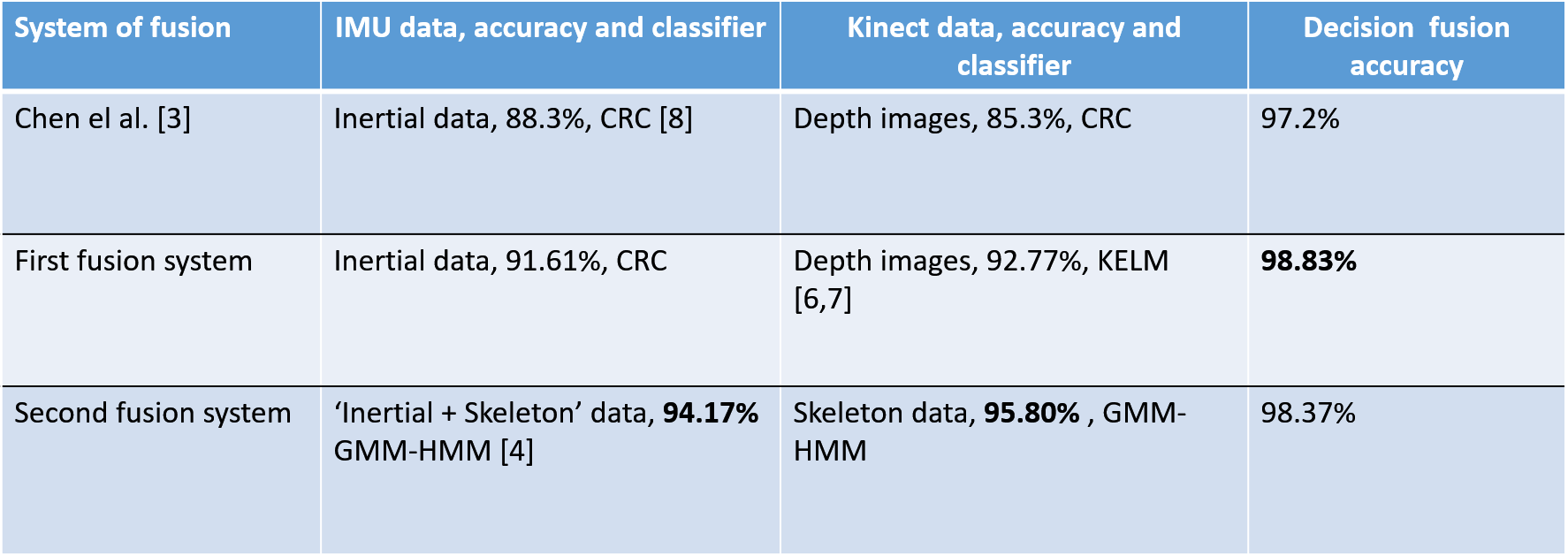
Table 2: Compare recognition accuracy of the proposed method on the UTD-MHAD dataset with state of the art in the subject specific experiment.
VI. Future Work and conclusion
A. Future Work
-
1. New dataset
(continuous monitoring of activities):
a) Recording a new dataset using multiple MARG sensors on the most important locations which is allowed to extract discriminative features.
b) The needed skeleton data in the beginning to link between those sensors.
c) Recalibrate those linked information again when the subject has the ability to face the camera.
-
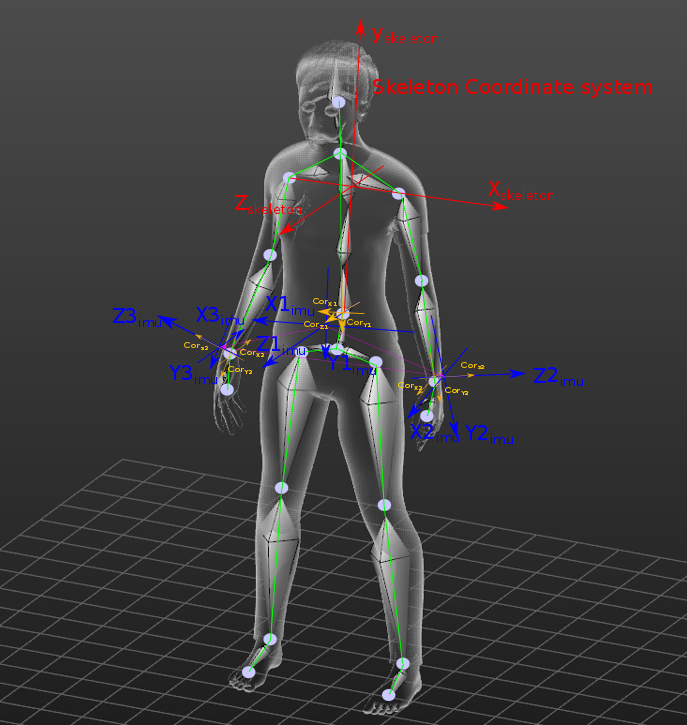
Figure 13: A proposed future work for recording a new dataset using multiple Magnetic, Angular Rate, and Gravity (MARG) sensors on the most important locations which is allowed to extract discriminative features.
-
2. Weighted Fusion of multiple
classifiers:
Another new way of fusing multiple classifiers in Decision-level fusion, named (weight decision-fusion), could be applied. Each sensor could provide different information from the other one and based on cross-validation strategy the weight of classifiers can be determined.
B. Conclusions
Different methods for Representing and analyzing human activities by utilizing space-time information.
Two frameworks designed and implemented for creating a robust system by fusing multiple sensors.
- a) The first fusion system combines the depth features from Kinect camera and statistical features from inertial sensors, and then decision-level fusion applied for different classifiers (CRC is used for Inertial features and KELM is used for depth features).
- b) The second fusion system, two different fusion had been used to extract global and local invariant-view features from skeleton and 'IMU + skelton' data respectively. Moreover, Gaussian mixtures are used for representing several poses and Hidden Markov Model to establish the sequence of these poses for describing every action, which can cope with motion speed variations in actions. Those Multiple "GMM based HMM" classifiers from global and local descriptors were fused to enhance the recognition rate.
References
[1] Chen Chen, Roozbeh Jafari, and Nasser Kehtarnavaz. “UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor”. In: Image Processing (ICIP), 2015 IEEE International Conference on. IEEE. 2015, pp. 168–172.
[2] Kui Liu et al. “Fusion of inertial and depth sensor data for robust hand gesture recognition”. In: IEEE Sensors Journal 14.6 (2014), pp. 1898–1903
[3] Chen Chen, Roozbeh Jafari, and Nasser Kehtarnavaz. “A real-time human action recognition system using depth and inertial sensor fusion”. In: IEEE Sensors Journal 16.3 (2016), pp. 773–781.
[4] Jose Israel Figueroa-Angulo et al. “Compound Hidden Markov Model for Activity Labelling”. In: International Journal of Intelligence Science 5.05 (2015), p. 177.
[5] Sebastian OH Madgwick, Andrew JL Harrison, and Ravi Vaidyanathan. “Estimation of IMU and MARG orientation using a gradient descent algorithm”. In: 2011 IEEE International Conference on Rehabilitation Robotics. IEEE. 2011, pp. 1–7.
[6] Erik Cambria et al. “Extreme learning machines [trends & controversies]”. In: IEEE Intelligent Systems 28.6 (2013), pp. 30–59.
[7] Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew. “Extreme learning machine: theory and applications”. In: Neurocomputing 70.1 (2006), pp. 489–501.
[8] Lei Zhang, Meng Yang, and Xiangchu Feng. “Sparse representation or collaborative representation: Which helps face recognition?” In: 2011 International Conference on Computer Vision. IEEE. 2011, pp. 471–478.
[9] Chen Chen, Roozbeh Jafari, and Nasser Kehtarnavaz. “Improving human action recognition using fusion of depth camera and inertial sensors”. In: IEEE Transactions on Human-Machine Systems 45.1 (2015), pp. 51–61.
[10] Chen Chen, Roozbeh Jafari, and Nasser Kehtarnavaz. “Fusion of depth, skeleton, and inertial data for human action recognition”. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE. 2016, pp. 2712–2716.
[11] Enea Cippitelli et al. “Time synchronization and data fusion for RGB-depth cameras and inertial sensors in AAL applications”. In: 2015 IEEE International Conference on Communication Workshop (ICCW). IEEE. 2015, pp. 265–270.
[12] Samuele Gasparrini et al. “Proposal and experimental evaluation of fall detection solution based on wearable and depth data fusion”. In: ICT Innovations 2015. Springer, 2016, pp. 99–108.
[13] Bogdan Kwolek and Michal Kepski. “Human fall detection on embedded platform using depth maps and wireless accelerometer”. In: Computer methods and programs in biomedicine 117.3 (2014), pp. 489–501.
[14] Bogdan Kwolek and Michal Kepski. “Improving fall detection by the use of depth sensor and accelerometer”. In: Neurocomputing 168 (2015), pp. 637–645.s